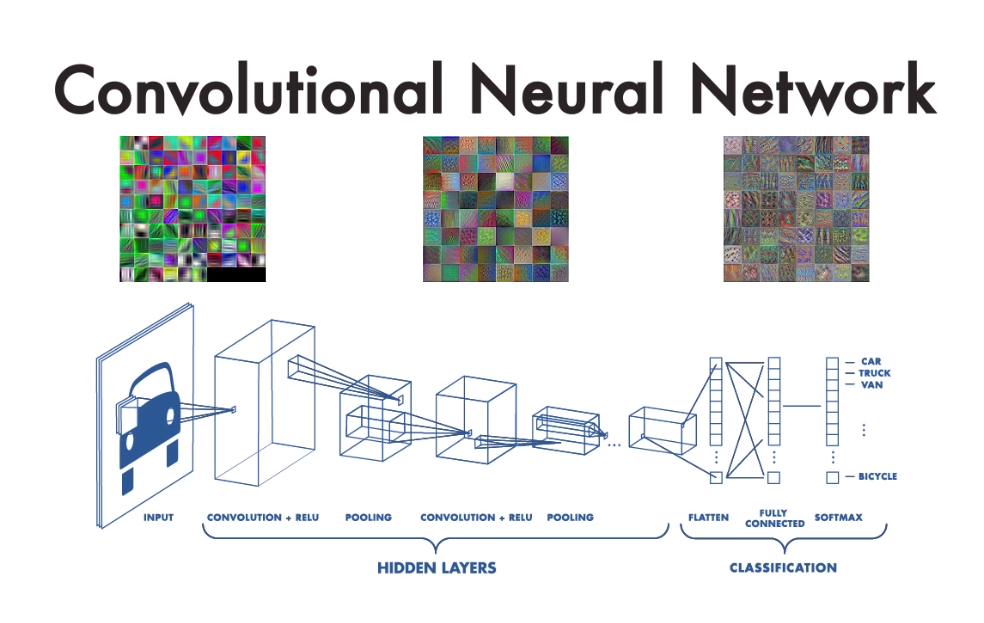
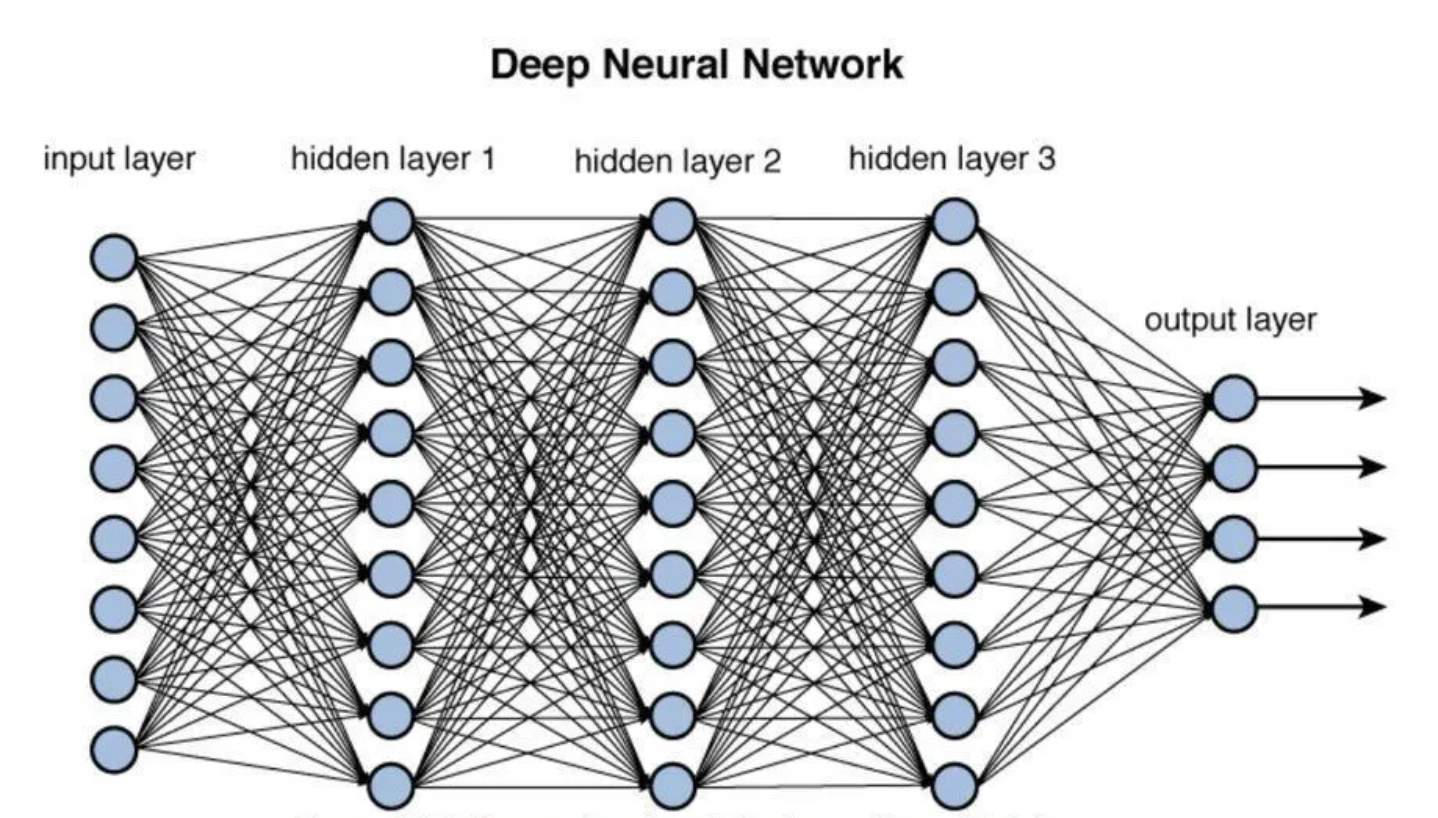
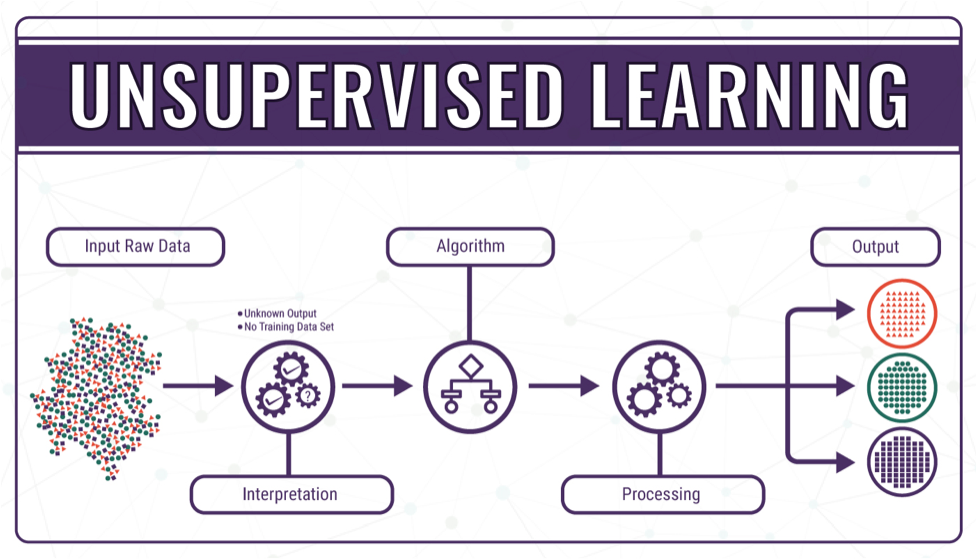
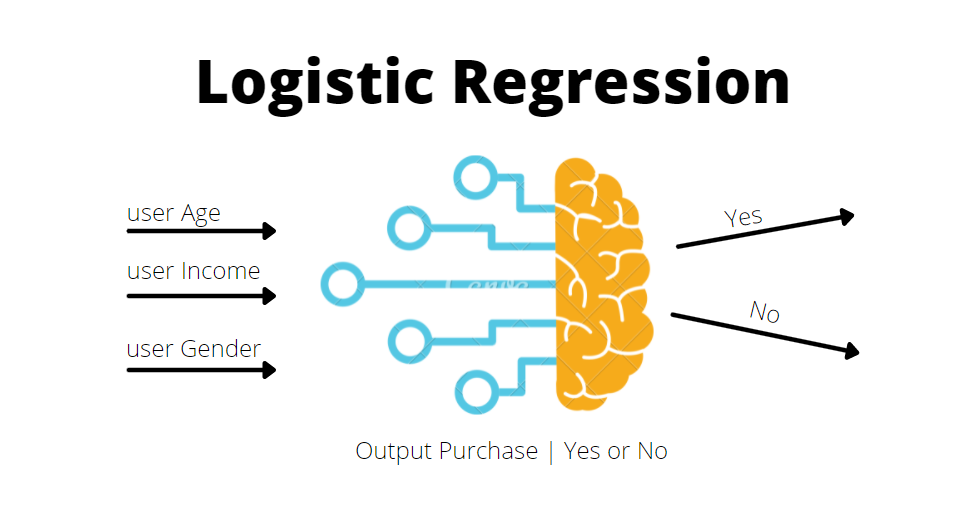
개체명 인식(Named Entity Recognition)
NER(Named Entity Recognition)은 자연어 처리(Natural Language Processing, NLP)의 한 영역으로, 텍스트에서 사람, 조직, 위치, 날짜, 시간, 통화, 비율과 같은 명명된 엔티티(명사)를 식별하고 분류하는 기술이다. NER 시스템은 주어진 문서에서 중요한 정보를 추출하는 데 사용되며, 정보 검색, 질의 응답 시스템, 콘텐츠 요약, 고객 지원 시스템, 그리고 감정 분석 등 다양한 NLP 응용 프로그램에 활용된다.