AI-System-Builiding-and-Operating
AI 시스템 구축과 운영(아키텍처, 배포, 모니터링) 관련 정리

AI-System-Builiding-and-Operating
AI 시스템 구축과 운영(아키텍처, 배포, 모니터링) 관련 정리

AI 모델 개발 전 과정(문제정의, 데이터, 학습/평가, 배포/모니터링) 실무 가이드를 정리

AI 모델 성능을 끌어올리는 데이터 전처리, 결측치, 이상치, 스케일링, 인코딩, 데이터 분리, 파이프라인 자동화까지 실무 위주로 정리.

GPU 서버에 도커 이미지로 JupyterLab 배포하기
GPU서버에서 딥러닝모델 학습을 위해 JupyterLab을 도커파일로 만들어 실행하는 방법을 정리해보겠다.

RNN(Recurrent Neural Network, 순환 신경망)은 시퀀스 데이터를 처리하기 위해 설계된 인공 신경망의 한 종류이다. RNN은 시간에 따라 정보를 전달할 수 있는 내부 메모리를 가지고 있어, 시퀀스의 길이에 상관없이 입력데이터 사이의 장기 의존성을 학습할 수 있다. 이러한 특성으로 인해 RNN은 자연어 처리(NLP), 음성 인식, 시계열 예측 등 시퀀스 데이터를 다루는 다양한 분야에서 활용된다.
출처 : 혼자 공부하는 머신러닝+딥러닝 9장. 텍트를 위ㄴ 인공 신경망]
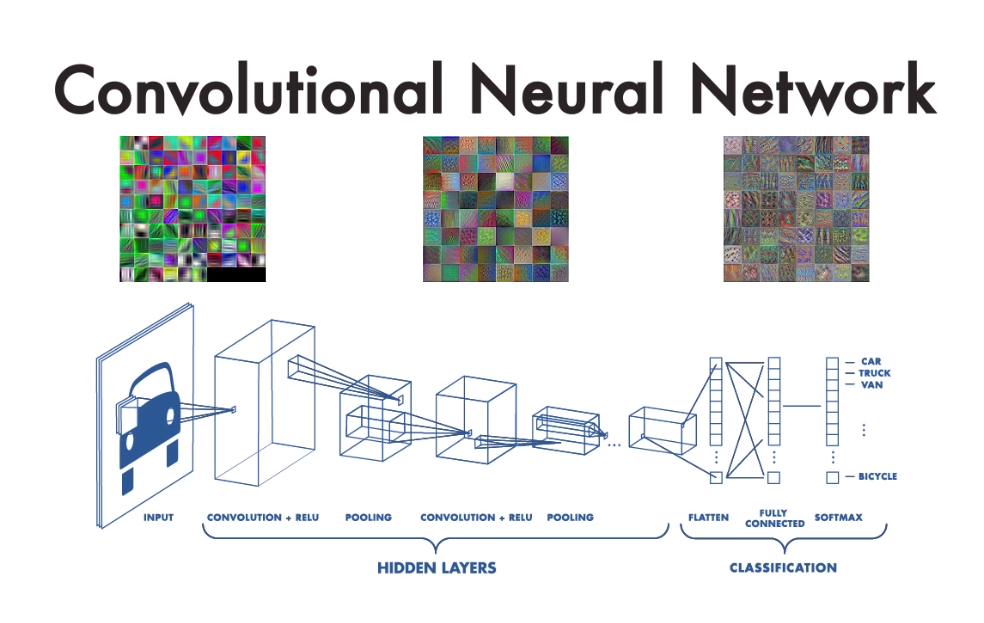
이번에는 저번 편에서 저장한 합성곱 신경망 모델을 읽어 들인 후 모델의 가중치와 특성 맵을 시각화해본다. 또한 케라스의 함수형 API를 사용하여 모델의 조합을 자유롭게 구성해본다.
[출처 : 혼자 공부하는 머신러닝+딥러닝 8장. 이미지를 위한 인공신경망]

개체명 인식(Named Entity Recognition)
NER(Named Entity Recognition)은 자연어 처리(Natural Language Processing, NLP)의 한 영역으로, 텍스트에서 사람, 조직, 위치, 날짜, 시간, 통화, 비율과 같은 명명된 엔티티(명사)를 식별하고 분류하는 기술이다. NER 시스템은 주어진 문서에서 중요한 정보를 추출하는 데 사용되며, 정보 검색, 질의 응답 시스템, 콘텐츠 요약, 고객 지원 시스템, 그리고 감정 분석 등 다양한 NLP 응용 프로그램에 활용된다.
합성곱 신경망(Convolutional Neural Network, CNN)은 주로 이미지 인식, 영상 처리, 컴퓨터 비전 분야에서 사용되는 심층 신경망의 한 종류이다. CNN은 이미지로부터 패턴을 인식하고 이해하는 데 특화되어 있으며, 이를 위해 합성곱 계층(convolutional layer)과 풀링 계층(pooling layer)을 포함한 특별한 구조를 가진다.
[출처 : 혼자 공부하는 머신러닝+딥러닝 8장. 이미지를 위한 인공신경망]

인공 신경망과 심층 신경망을 구성하고 다양한 옵티마이저를 통해 성능을 향상시킬 수 있는 방법에 대해 알아보았다.
이번에는 과대적합을 막기 위해 신경망에서 사용하는 규제방법인 드롭아웃, 최상의 훈련 모델을 자동으로 저장하고 유지하는 콜백과 조기종료를 알아보겠다.
[출처 : 혼자 공부하는 머신러닝+딥러닝 7장. 인공 신경망]
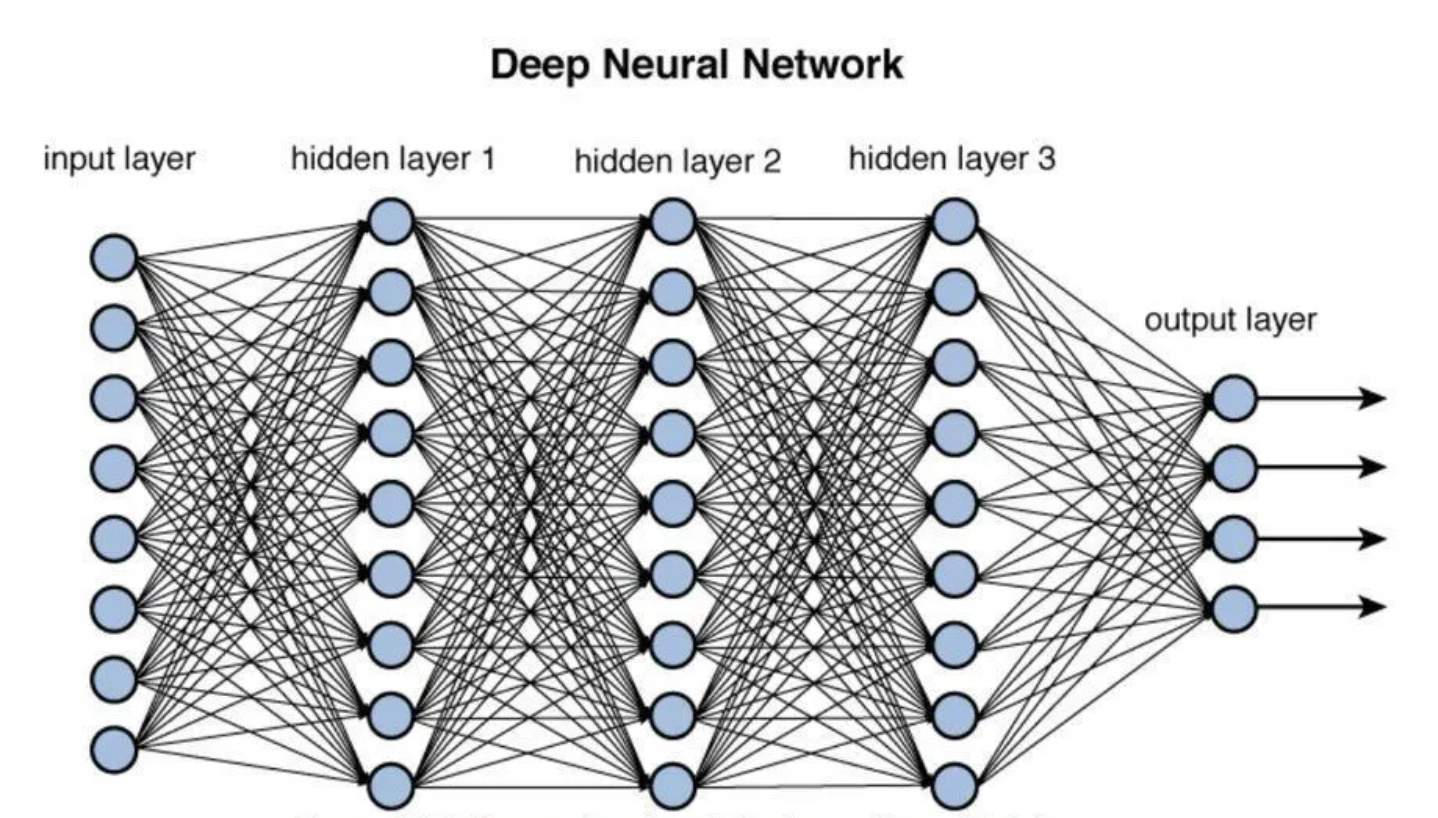
심층 신경망(Deep Neural Network, DNN)은 여러 개의 은닉층을 포함하는 인공 신경망의 한 종류이다. 인공 신경망은 입력층(input layer), 하나 이상의 은닉층(hidden layers), 그리고 출력층(output layer)으로 구성되며, 이 중에서 은닉층이 여러 개인 경우를 심층 신경망이라고 한다. 심층 신경망은 복잡한 데이터에서 높은 수준의 추상화와 패턴 인식을 수행할 수 있으며, 이미지 인식, 자연어 처리, 음성 인식 등 다양한 분야에서 광범위하게 활용된다.
[출처 : 혼자 공부하는 머신러닝+딥러닝 7장. 인공 신경망]