
순차데이터와 순환신경망
RNN(Recurrent Neural Network, 순환 신경망)은 시퀀스 데이터를 처리하기 위해 설계된 인공 신경망의 한 종류이다. RNN은 시간에 따라 정보를 전달할 수 있는 내부 메모리를 가지고 있어, 시퀀스의 길이에 상관없이 입력데이터 사이의 장기 의존성을 학습할 수 있다. 이러한 특성으로 인해 RNN은 자연어 처리(NLP), 음성 인식, 시계열 예측 등 시퀀스 데이터를 다루는 다양한 분야에서 활용된다.
출처 : 혼자 공부하는 머신러닝+딥러닝 9장. 텍트를 위ㄴ 인공 신경망]
순차 데이터(Sequential Data)
순서가 있는 데이터를 말한다. 이러한 데이터는 특정 순서대로 나ㅕㄹ되어 있으며, 각 데이터 포인트 사이에는 시간적 또는 공간적 연관성이 존재한다. 순차 데이터의 한 요소는 그 전후의 요소와 관련이 있으며, 이러한 연속성 때문에 데이터 전체를 통해 패턴이나 관계를 찾아낼 수 있다.
ex) 글, 대화, 일자별 날씨, 일자별 판매 실적
순환 신경망
일반적인 완전 연결 신경망과 거의 비슷하나, 이전 데이터의 처리 흐름을 순환하는 고리 하나가 추가된다. 뉴런의 출력이 다시 자기 자신으로 전달되는데, 즉 어떤 샘플을 처리할 때 바로 이전에 사용했던 데이터를 재사용하는 것이다. 이렇게 샘플을 처리하는 한 단계를 타임스텝이라고 부르며, 순환신경망은 이전 타임스텝의 샘플을 기억하지만, 타임스텝이 오래될수록 순환되는 정보는 희미해진다.
순환 신경망에서는 특별히 층을 셀이라고 부른다. 한 셀에는 여러개의 뉴런이 있지만, 뉴런을 모두 표시하지 않고 하나의 셀로 층을 표현한다. 또 셀의 출력을 은닉 상태라고 부른다.
입력에 어떤 가중치를 곱하고, 활성화 함수를 통과시켜 다음층으로 보내는 구조는 합성곱 신경망과 같으나, 층의 출력을 다음 타임 스텝에 재사용하는 것이 다르다.
은닉층의 활성화 함수로는 하이퍼볼릭 탄젠트(tanh)를 사용한다. 시그모이드 함수와는 달리 -1 ~ 1 사이의 범위를 가진다.
RNN의 주요 특징
- 순환 구조 : RNN은 네트워크 내에서 정보를 순환시키는 구조를 가지고 있어, 이전의 계산 결과를 현재의 계산에 활용할 수 있다. 이를 통해 시퀀스 내의 정보를 시간적으로 연결하여 처리한다.
- 변동하는 시퀀스 길이 처리 : RNN은 입력 시퀀스의 길이가 변동적인 데이터를 처리할 수 있다. 이는 고정된 크기의 입력을 다루는 다른 신경망 모델과는 차별되는 특징이다.
- 파라미터 공유 : 시퀀스의 각 지점(time step)마다 동일한 가중치를 사용함으로써, 모델의 파라미터 수를 효율적으로 관리한다.
활용 분야
- 자연어 처리 : 문장, 문서분류, 기계 번역, 감성 분석 등 NLP의 여러 작업에서 사용된다.
- 음성 인식 : 오디오 시퀀스에서 음성을 텍스트로 변환하는 작업에 사용된다.
- 시계역 예측 : 주식 가격, 기상 상태 등 시간에 따라 변하는 데이터의 미래 값을 예측하는 데 사용된다.
한계
- 장기 의존성 문제 : RNN은 이론적으로는 시퀀스의 장기 의존성을 학습할 수 있지만, 실제로는 그레디언트 소실(vanishing gradient) 또는 폭발(exploding gradient) 문제로 인해 학습이 어려울 수 있다.
- 계산 비용 : 순환 구조로 인해 병렬 처리가 어렵고, 긴 시퀀스를 처리할 때 계산 비용이 높아질 수 있다.
이러한 한계를 극복하기 위해 LSTM(Long Short-Term Memory)이나 GRU(Gated Recurrent Unit)와 같은 고급 RNN 구조가 개발되었다. 이들은 장기 의존성을 더 효과적으로 학습할 수 있는 메커니즘을 제공한다.
IMDB 리뷰 분류
1. 데이터 준비하기
IMDB 리뷰 데이터셋을 적재한다. 리뷰를 감상평에 따라 긍정과 부정으로 분류해 놓은 데이터셋인데, 총 50,000개의 샘플로 이루어져 있고 훈련 데이터와 테스트 데이터에 25,000개씩 나누어져 있다.
실제 IMDB 리뷰 데이터셋은 영어로 된 문장이지만, 텐서플로에는 이미 정수로 바꾼 데이터가 포함되어 있다. 여기에는 가장 자주 등장하는 단어 500개만 사용한다.
1 | from tensorflow.keras.datasets import imdb |
1 | (25000, ) (25000, ) |
첫 번째 리뷰의 길이는 218개의 토큰, 두 번째는 189개의 토큰으로 이루어져있다.
1 | print(train_input[0]) |
1 | [1, 14, 22, 16, 43, 2, 2, 2, 2, 65, 458, 2, 66, 2, 4, |
텐서플로의 IMDB 리뷰 데이터는 정수로 변환되어 있다. num_words=500으로 지정했기 때문에 어휘 사전에 없는 단어는 모두 2로 표시된다.
1 | print(train_target[:20]) |
1 | [1 0 0 1 0 0 1 0 1 0 1 0 0 0 0 0 1 1 0 1] |
타깃 데이터는 0(부정)과 1(긍정)으로 나누어진다.
1 | from sklearn.model_selection import train_test_split |
훈련 데이터의 20% 정도를 검증세트로 떼어 놓는다.
2. 데이터 분석과 패딩
평균적인 리뷰, 가장 짧은 리뷰, 가장 긴 리뷰의 길이를 확인하기 위해 먼저 각 리뷰의 길이를 계산해 넘파이 배열에 담아 그래프로 표현한다.
1 | import numpy as np |
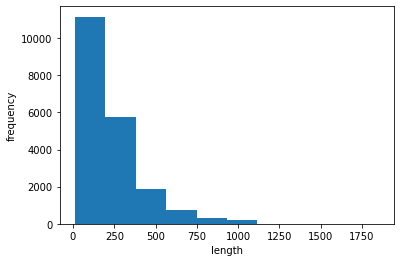
대부분 리뷰 길이는 300개 미만인 것을 볼 수 있다.
리뷰는 대부분 짧기 때문에 이 예제에서는 100개의 단어만 사용하기로 한다.
이 리뷰들의 길이를 맞추기 위해 패딩이 필요하다.
pad_sequences()함수를 통해 시퀀스 데이터의 길이를 맞출 수 있다.
짧은 리뷰는 앞에서부터 0토큰을 채우고, 긴 리뷰는 잘라내는데, 만약 pad_sequences()의 매개변수 padding을 기본값인 pre에서 post로 바꾸면 샘플의 뒷부분으로 패딩할 수 있다.
1 | from tensorflow.keras.preprocessing.sequence import pad_sequences |
1 | (20000, 100) |
train_seq는 이제 (20000, 100) 크기의 2차원 배열임을 알 수 있다.
3. 원-핫 인코딩으로 데이터 바꾸기
케라스는 여러 종류의 순환층 클래스를 제공하는데, 가장 간단한 것은 SimpleRNN 클래스이다. 이 문제는 이진 분류이므로 마지막 출력층은 1개의 뉴런을 가지고 시그모이드 활성화 함수를 사용한다.
1 | from tensorflow import keras |
뉴런 갯수를 8개로 지정하고, 샘플의 길이가 100이고 500개의 단어만 사용하도록 설정했기 때문에 input_Shape를 (100, 500)으로 둔다.
순환층도 활성화 함수를 사용하는데 기본 매개변수 activation의 의 기본값은 tanh로, 하이퍼볼릭 탄젠트 함수를 사용한다.
그러나 토큰을 정수로 변환한 데이터를 신경망에 주입하면, 큰 정수가 큰 활성화 출력을 만들게 된다. 이 정수들 사이에는 어떤 관련이 없기 때문에 정수값에는 있는 크기 속성을 없애고 각 정수를 고유하게 표현하기 위해 원-핫 인코딩을 사용한다.
keras.utils 패키지의 to_categorical() 함수를 사용하여 훈련세트와 검증 세트를 원-핫 인코딩으로 바꾸어준다.
1 | train_oh = keras.utils.to_categorical(train_seq) |
1 | (20000, 100, 500) |
정수 하나마다 500차원의 배열로 변경되었다.
1 | print(train_oh[0][0][:12]) |
1 | [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0.] |
첫 리뷰의 첫 단어를 원-핫 인코딩시킨 결과이다.
모든 원소의 값을 더하면 1임을 알 수 있다.
4. 순환 신경망 훈련하기
RMSprop의 기본 학습률 0.001을 사용하지 않기 위해 별도의 RMSprop 객체를 만들어 학습률을 0.0001로 지정한다.
install_url to use ShareThis. Please set it in _config.yml.