
인공 신경망 (Artificial Neural Network)
인공 신경망(Artificial Neural Network, ANN)은 인간의 뇌 구조와 기능을 모방하여 만들어진 컴퓨팅 시스템이다. 인공 신경망은 데이터를 처리하고 학습하는데 사용되며, 주로 패턴 인식, 분류, 예측 등과 같은 다양한 머신러닝과 딥러닝 문제를 해결하는 데 활용한다. 생물학적 뉴런에서 영감 받아 만든 머신러닝 알고리즘이지만, 실제 우리 뇌를 모델링한 것은 아니다. 신경망은 기존 머신러닝 알고리즘으로 다루기 어려웠던 이미지, 음성, 텍스트 분야에서 뛰어난 성능을 발휘하면서 크게 주목받고 있다. 인공 신경망 알고리즘을 종종 딥러닝이라고 부른다.
[출처 : 혼자 공부하는 머신러닝+딥러닝 7장. 인공 신경망]
1. 패션 MNIST
딥러닝을 배울 때 많이 쓰는 데이터셋이 MNIST 데이터셋이다.
10종류의 패션 아이템으로 구성되어있다.
keras.datasets.fashion_mnist모듈 아래 load_data() 함수로 훈련 데이터와 테스트 데이터를 얻을 수 있다.
1 | from tensorflow import keras |
1 | (60000, 28, 28) (60000,) |
28*28 사이즈의 이미지가 훈련세트에는 6만개, 테스트세트에는 1만개 들어있다.
훈련 데이터에서 몇 개의 샘플을 그림으로 표현해본다.
1 | import matplotlib.pyplot as plt |

1 | import numpy as np |
1 | (array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8), array([6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000])) |
1 | 각 레이블 : |
각 레이블마다 6000개의 샘플이 들어있다.
2. 로지스틱 회귀로 패션 아이템 분류하기
이 훈련 샘플은 60,000개나 되기 때문에, 전체 데이터를 한꺼번에 사용하여 모델을 훈련시키기보다, 샘플을 하나씩 꺼내서 모델을 훈련하는 방법이 효율적이다.
이 상황에서 가장 잘 맞는 방법은 확률적 경사 하강법이다.SGDClassifier 클래스의 매개변수 loss='log'로 지정하여 확률적 경사 하강법 모델을 만든다.
2-1. 데이터를 표준화 전처리하기
확률적 경사 하강법은 여러 특성 중 기울기가 가장 가파른 방향을 따라 이동한다. 특성마다 값의 범위가 다르다면 올바르게 손실 함수의 경사를 내려올 수 없다.
이 데이터셋의 각 픽셀은 0255 사이의 정수값을 가지기 때문에, 255로 나누어 01 사이의 값으로 정규화한다.
1 | train_scaled = train_input / 255.0 |
- SGDClassifier는 2차원 입력을 다루지 못하기 때문에 각 샘플을 1차원 배열로 만들어야 한다.
- reshape() 메서드의 두 번째 매개변수를 28*28 이미지 크기에 맞게 지정하면 척 번째 차원은 변하지 않고, 원본 데이터의 두 번째, 세 번째 차원이 1차원으로 합쳐진다.
1 | print(train_scaled.shape) |
1 | (60000, 784) |
2-2. 모델을 만들고 교차검증하기
SGDClassifier 클래스와 cross_validate()로 교차검증을 진행한다.
1 | from sklearn.model_selection import cross_validate |
1 | 0.8196000000000001 |
2-3. 로지스틱 회귀 공식 복습
앞서 배운 로지스틱 회귀 공식은 이렇다.z = a * weight + b * length + ... + f
이를 MNIST 데이터셋에 적용하면 이렇다.z_티셔츠 = w1 * 픽셀1 + w2 * 픽셀2 + ... + w784 * 픽셀784 + bz_바지 = w1' * 픽셀1 + w2' * 픽셀2 + ... + w784' * 픽셀784 + b'
이와 같이 10개의 클래스에 대한 선형 방정식을 구한 뒤, 소프트맥스 함수를 통과하여 각 클래스에 대한 확률을 얻을 수 있다.
2-4. SGDClassifier 복습
SGDClassifier는 사이킷런(Scikit-learn) 라이브러리에서 제공하는 확률적 경사 하강법(Stochastic Gradient Descent, SGD)을 사용한 선형 분류기이다. “SGD”는 반복적으로 주어진 데이터셋을 작은 배치로 나누어 모델의 가중치를 업데이트하는 최적화 알고리즘을 말하며, 이를 통해 분류 또는 회귀 문제를 해결할 수 있다.
SGDClassifier는 특히 대규모 데이터셋에 대한 선형 분류 문제에 효과적인 방법으로 널리 사용된다. 이 클래스는 다양한 선형 모델, 예를 들어 로지스틱 회귀(Logistic Regression), 선형 서포트 벡터 머신(Linear Support Vector Machine) 등을 구현할 수 있도록 지원한다.
주요 기능 및 특징:
- 효율성: 대규모 데이터셋에 대해 효율적인 학습이 가능하다.
- 유연성: 다양한 손실 함수(Loss Function)를 지원하며, 이를 통해 다양한 선형 분류 문제를 해결할 수 있다. 예를 들어,
loss="hinge"는 선형 SVM을,loss="log"는 로지스틱 회귀를 의미합니다. - 정규화:
l2,l1,elasticnet과 같은 정규화 옵션을 제공하여 모델의 복잡도를 조절하고, 과적합을 방지할 수 있다. - 온라인 학습 지원:
partial_fit메서드를 사용하여 데이터가 순차적으로 도착할 때 모델을 점진적으로 업데이트할 수 있다.
사용 예시:
1 | from sklearn.linear_model import SGDClassifier |
이 코드는 먼저 가상의 분류 데이터셋을 생성하고, SGDClassifier를 사용하여 선형 SVM 모델 (loss-"hinge")을 학습한 뒤, 몇 개의 샘플에 대해 예측을 수행한다.SGDClassifier는 특히 대규모 데이터셋을 다룰 때 그 장점이 두드러지며, 다양한 선형 분류 문제에 적용될 수 있다.
3. 인공신경망으로 모델 만들기
3-1. 인공 신경망
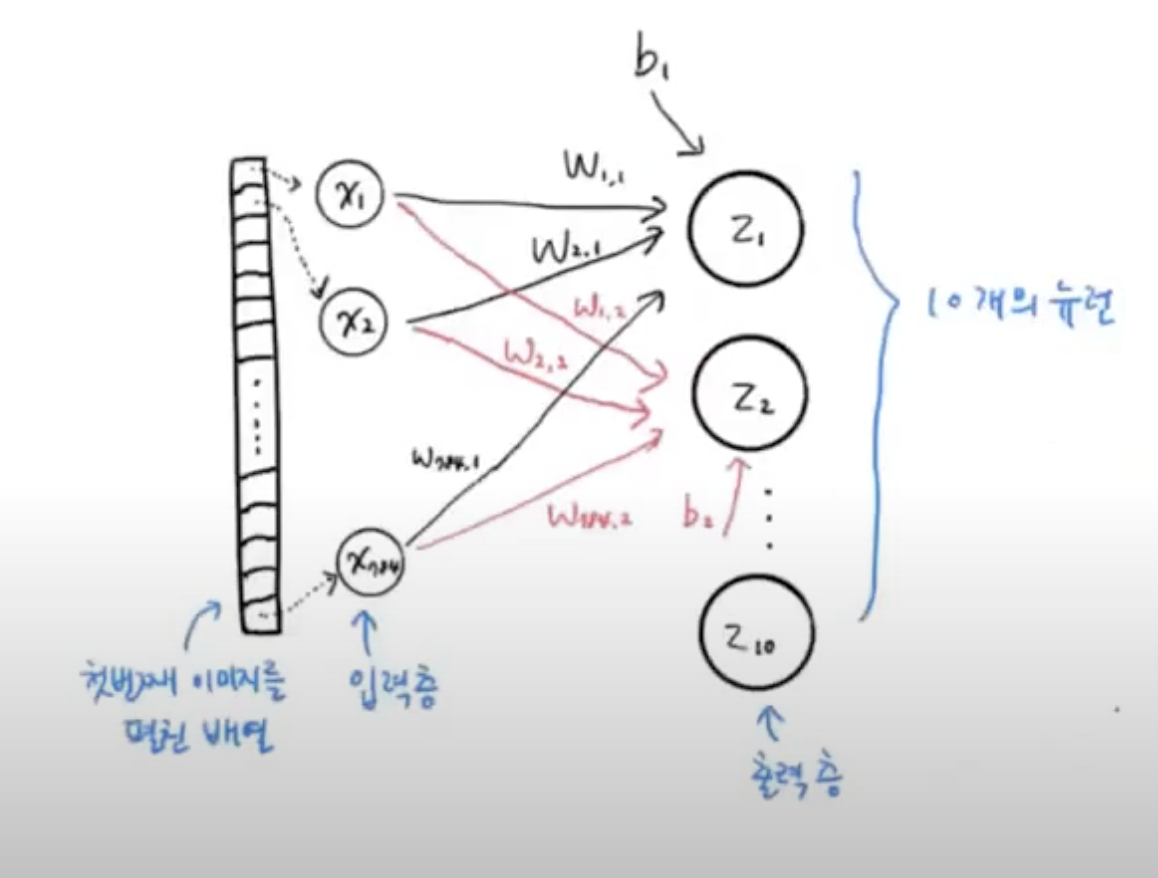
가장 간단한 인공 신경망은 출력층 하나가 있는 인공 신경망이다.
확률적 경사 하강법을 사용하는 로지스틱 회귀와 같다.
보통 인공 신경망을 이야기 할 때나 딥러닝을 이야기 할 때는 출력층 하나가 아니라 더 많은 층이 있는 경우를 이야기한다.
- 입력층 : 픽셀값 자체이고, 특별한 계산을 수행하지 않는다.
- 출력층 : z1 ~ z10을 계산하고 이를 바탕으로 클래스를 예측
- 뉴런 : z값을 계산하는 단위, 뉴런에서 일어나는 일은 선형 계산이 전부이다. 이제는 뉴런이란 표현 대신
유닛(unit)이라고 부르는 사람이 더 많다.
3-2. 텐서플로우와 케라스

텐서플로우 : 구글이 2015년 11월 오픈소스로 공개한 딥러닝 라이브러리
케라스 : 텐서플로의 고수준 API
딥러닝 라이브러리가 다른 머신러닝 라이브러리와 다른 점 중 하나는 그래픽 처리 장치인 GPU를 사용하여 인공 신경망을 훈련한다는 것이다. GPU는 벡터와 행렬 연산에 매우 최적화되어 있기 때문에 곱셈과 덧셈이 많이 수행되는 인공 신경망에 큰 도움이 된다.
케라스 라이브러리는 직접 GPU 연산을 수행하지 않는다. 대신 GPU 연산을 수행하는 다른 라이브러리를 백엔드로 사용한다. 예를 들면 텐서플로가 케라스의 백엔드 중 하나이다. 이런 케라스를 멀티-백엔드 케라스라고 부른다. 케라스 API만 익히면 다양한 딥러닝 라이브러리를 입맛대로 골라서 쓸 수 있다.
3-3. 케라스 모델 만들기
인공신경망에서는 교차 검증을 잘 사용하지 않고, 검증 세트를 별도로 덜어 내어 사용한다. 데이터셋이 충분히 크고, 교차검증에는 오랜시간이 걸리기 때문이다.
1 | from sklearn.model_selection import train_test_split |
1 | (48000, 784) (48000,) |
가장 기본이 되는 층인 밀집층을 만들어본다.
입력층은 784개의 뉴런으로 구성되며, 출력층은 10개의 뉴런으로 구성된다.
밀집층은 각 뉴런이 모두 연결되어야 하기 때문에, 784*10 = 7840개의 선이 포함된다.
이를 완전 연결층이라고도 부른다.
1 | dense = keras.layers.Dense(10, activation='softmax', input_shape=(784, )) |
뉴런의 갯수를 10으로 지정하고, 10개의 뉴런에서 출력되는 값을 확률로 바꾸기 위해 소프트맥스 함수를 이용한다. 만약 이진분류라면 activation='sigmoid'로 입력한다.
이후 밀집층을 가진 신경망 모델을 만들기 위해 Sequential클래스를 사용한다.
소프트맥스와 같이 뉴런의 선형방정식 계산 결과에 적용되는 함수를 활성화 함수라고 부른다.
케라스 모델은 훈련하기 전 설정 단계가 있다.
1 | model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy') |
loss매개변수에 이진 분류라면 binary_crossentropy, 다중 분류라면 categorical_crossentropy를 사용한다.
정수로 된 타깃값을 원-핫 인코딩으로 바꾸지 않고 사용하려면 loss='sparse_categorical_crossentropy',
타깃값을 원-핫 인코딩으로 준비했다면 loss='categorical_crossentropy'으로 지정한다.
metrics 매개변수는 accuracy를 지정하면 에포크마다 정확도를 함께 출력해준다.
1 | model.fit(train_scaled, train_target, epochs=5) |
1 | Epoch 1/5 |
epochs 매개변수로 에포크 횟수를 지정할 수 있다.evaluate() 메서드로 모델의 성능을 평가해본다.
1 | model.evaluate(val_scaled, val_target) |
1 | 375/375 [==============================] - 1s 3ms/step - loss: 0.4630 - accuracy: 0.8458 |
fit() 메서드와 비슷한 출력을 보여준다.
인공 신경망 (Artificial Neural Network)
https://hamin7.github.io/2024/04/02/Artificial-Neural-Network/
install_url to use ShareThis. Please set it in _config.yml.