
선형회귀 알고리즘
지도 학습 알고리즘은 크게 분류와 회귀(regression)으로 나뉜다. 분류는 말 그대로 샘플을 몇 개의 클래스 중 하나로 분류하는 문제이다. 회귀는 클래스 중 하나로 분류하는 것이 아니라 임의의 어떤 숫자를 예측하는 문제이다.
예를 들면 내년도 경제 성장률을 예측하거나 배달이 도착할 시간을 예측하는 것이 회귀 문제이다. 회귀는 정해진 클래스가 없고 임의의 수치를 출력한다.
[출처 : 혼자 공부하는 머신러닝+딥러닝 3장. 회귀알고리즘과 모델규제]
K-최근접 이웃 회귀

(출처 : kNN 최근접 이웃 알고리즘)
녹색 영화는 액션영화일까? 로맨틱 영화일까?
녹색 영화는 액션 영화와 로맨틱 영화 가운데 있다.
그래서 상당히 답을하기 곤란한 상황이다.
현실 세계에서 이게 액션 영화다 로맨틱 영화다 라고 딱 부러지게 얘기하기는 어렵다.
이럴 경우에 머신러닝을 사용해 예측갑을 가지고 이야기 할 수가 있다.
그래서 기존의 데이터, 녹색 별을 제외한 기존의 데이터를 중심으로 이 녹색영화가 액션 영화다, 로맨틱 영화다라고 이야기 하는 방법이 knn 알고리즘이다.
y축에 보이는 것처럼 발차기 횟수가 많을 경우에는 액션 영화의 가능성이 크고
x축의 키스 횟수가 많을때는 로맨틱 영화다라고 볼 수가 있다.
그렇다면 여기서 knn 알고리즘을 간단하게 살펴보도록 하겠다.
일단은 k를 정해줘야 한다.
k는 최근접점을 우리가 몇개까지 볼것인지 정하는 것이다.
일단 k=3으로 쓰겠다. 이것으로 한번 예측값을 내보도록 하겠다.
k는 기본적으로 홀수를 쓴다. 왜냐하면 짝수로 쓰면 2:2와 같은 상황이 되어 답을 할 수 없는 상황이 되기 때문이다.
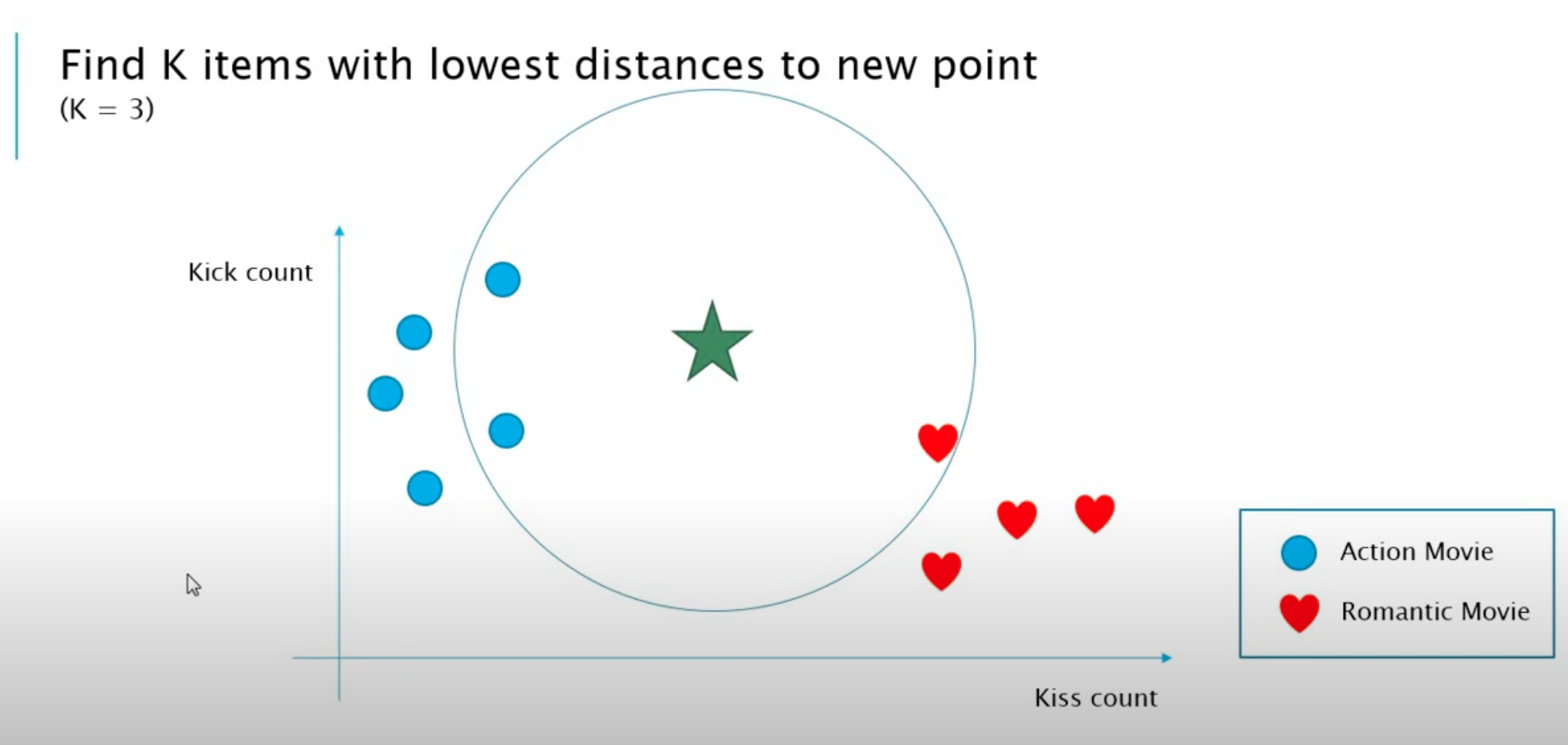
위 그래프에서 보이는 것처럼 최근접 거리에 있어 써클안에 액션 영화가 2개가 있고
로맨틱 영화가 하나가 있다.
그래서 원 안에 로맨틱 영화보다 액션 영화가 더 많기 때문에 녹색 영화는 액션 영화에요 라고 예측 값을 리턴할 수 있다.
이것이 바로 knn 알고리즘의 핵심이다.
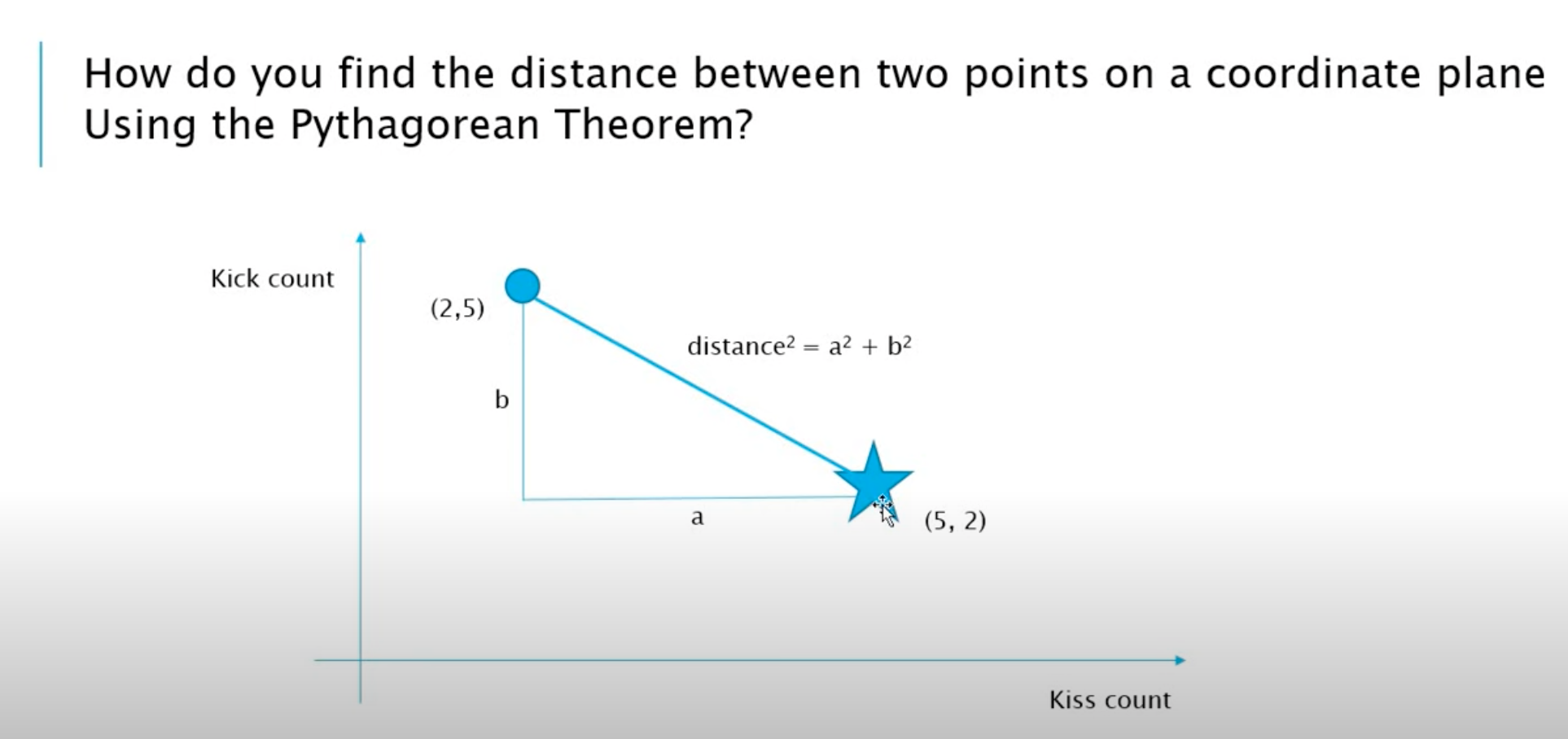
그렇다면 최근접점을 프로그램상에서 어떻게 구하는지 보자.
피타고라스의 정리를 이용해서 구한다.
두 정점의 거리를 구해서 가장 작은 거리의 점들부터 비교를 해나가는 것이다.
결정계수 (R^2)
과대적합
선형회귀
모델 파라미터
다항 회귀
특성 공학과 규제
다중 회귀
특성 공학
릿지
라쏘
하이퍼파라미터
install_url to use ShareThis. Please set it in _config.yml.